
Meta Platforms showed off a bevy of new AI features for its consumer-facing services Facebook, Instagram and WhatsApp at its annual Meta Connect conference in Menlo Park, California, this week.
But the biggest news from Mark Zuckerberg’s company may have actually come in the form of a computer science paper published without fanfare by Meta researchers on the open access and non-peer reviewed website arXiv.org.
The paper introduces Llama 2 Long, a new AI model based on Meta’s open source Llama 2 released in the summer, but that has undergone “continual pretraining from Llama 2 with longer training sequences and on a dataset where long texts are upsampled,” according to the researcher-authors of the paper.
As a result of this, Meta’s newly elongated AI model outperforms some of the leading competition in generating responses to long (higher character count) user prompts, including OpenAI’s GPT-3.5 Turbo with 16,000-character context window, as well as Claude 2 with its 100,000-character context window.
How LLama 2 Long came to be
Meta researchers took the original Llama 2 available in its different training parameter sizes — the values of data and information the algorithm can change on its own as it learns, which in the case of Llama 2 come in 7 billion, 13 billion, 34 billion, and 70 billion variants — and included more longer text data sources than the original Llama 2 training dataset. Another 400 billion tokens-worth, to be exact.
Then, the researchers kept the original Llama 2’s architecture the same, and only made a “necessary modification to the positional encoding that is crucial for the model to attend longer.”
That modification was to the Rotary Positional Embedding (RoPE) encoding, a method of programming the transformer model underlying LLMs such as Llama 2 (and LLama 2 Long), which essentially maps their token embeddings (the numbers used to represent words, concepts, and ideas) onto a 3D graph that shows their positions relative to other tokens, even when rotated. This allows a model to produce accurate and helpful responses, with less information (and thus, less computing storage taken up) than other approaches.
The Meta researchers “decreased the rotation angle” of its RoPE encoding from Llama 2 to Llama 2 Long, which enabled them to ensure more “distant tokens,” those occurring more rarely or with fewer other relationships to other pieces of information, were still included in the model’s knowledge base.
Using reinforcement learning from human feedback (RLHF), a common AI model training method where AI is rewarded for correct answers with human oversight to check it, and synthetic data generated by Llama 2 chat itself, the researchers were able to improve its performance in common LLM tasks including coding, math, language understanding, common sense reasoning, and answering a human user’s prompted questions.
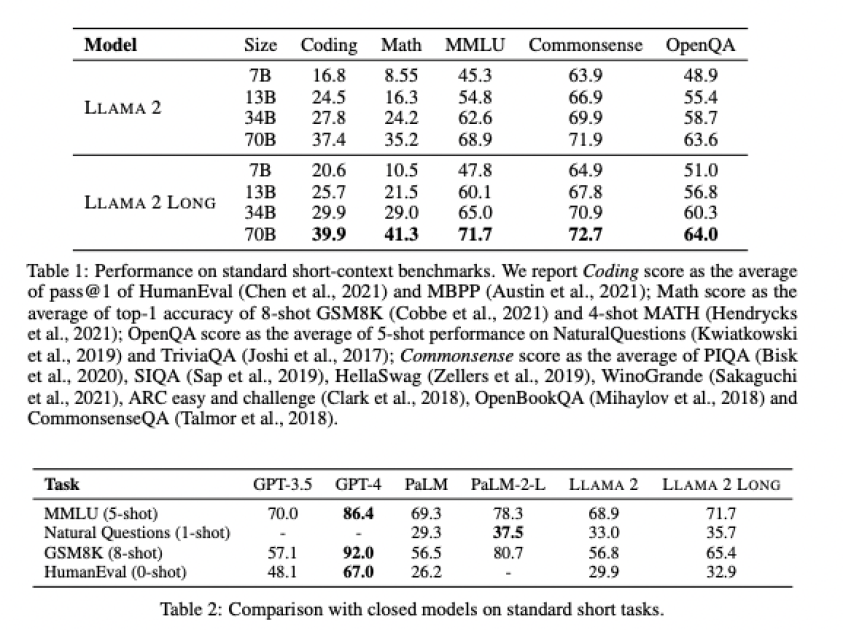
With such impressive results relative to both Llama 2 regular and Anthropic’s Claude 2 and OpenAI’s GPT-3.5 Turbo, it’s little wonder the open-source AI community on Reddit and Twitter and Hacker News have been expressing their admiration and excitement about Llama 2 since the paper’s release earlier this week — it’s a big validation of Meta’s “open source” approach toward generative AI, and indicates that open source can compete with the closed source, “pay to play” models offered by well-funded startups.
TechForgePulse's mission is to be a digital town square for technical decision-makers to gain knowledge about transformative enterprise technology and transact. Discover our Briefings.