
Even as the world bears witness to the power struggle and mass resignation at OpenAI, Microsoft, the long-time backer of the AI major, is not slowing down its own AI efforts. Today, the research arm of the Satya Nadella-led company dropped Orca 2, a pair of small language models that either match or outperform five to ten times larger language models, including Meta’s Llama-2 Chat-70B, when tested on complex reasoning tasks in zero-shot settings.
The models come in two sizes, 7 billion and 13 billion parameters, and build on the work done on the original 13B Orca model that demonstrated strong reasoning abilities by imitating step-by-step reasoning traces of bigger, more capable models a few months ago.
“With Orca 2, we continue to show that improved training signals and methods can empower smaller language models to achieve enhanced reasoning abilities, which are typically found only in much larger language models,” Microsoft researchers wrote in a joint blog post.
The company has open-sourced both new models for further research on the development and evaluation of smaller models that can perform just as well as bigger ones. This work can give enterprises, particularly those with limited resources, a better option to get to address their targeted use cases without investing too much in computing capacity.
Teaching small models how to reason
While large language models such as GPT-4 have long impressed enterprises and individuals with their ability to reason and answer complex questions with explanations, their smaller counterparts have largely missed that ability. Microsoft Research decided to tackle this gap by fine-tuning Llama 2 base models on a highly-tailored synthetic dataset.
However, instead of training the small models to replicate the behavior of more capable models – a commonly used technique known as imitation learning, the researchers trained the models to employ different solution strategies for different tasks at hand. The idea was that a larger model’s strategy may not work perfectly for a smaller one all the time. For example, GPT-4 may be able to answer complex questions directly but a smaller model, without that kind of capacity, might benefit by breaking the same task into a few steps.
“In Orca 2, we teach the model various reasoning techniques (step-by-step, recall then generate, recall-reason-generate, direct answer, etc.). More crucially, we aim to help the model learn to determine the most effective solution strategy for each task,” the researchers wrote in a paper published today. The training data for the project was obtained from a more capable teacher model in such a way that it teaches the student model to handle both aspects: how to use a reasoning strategy and when exactly to use it for a given task at hand.
Orca 2 performs better than larger models
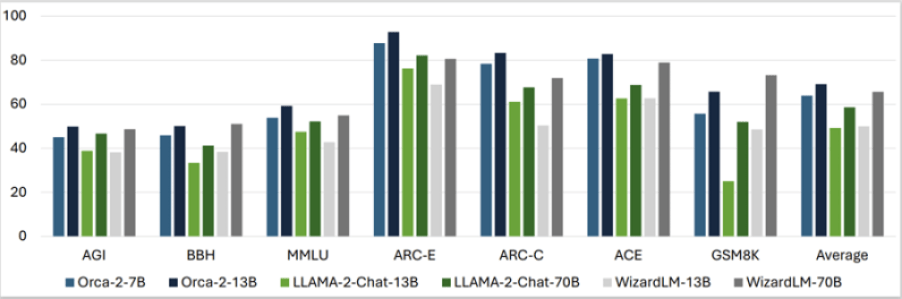
When tested on 15 diverse benchmarks (in zero-shot settings) covering aspects like language understanding, common-sense reasoning, multi-step reasoning, math problem solving, reading comprehension, summarizing and truthfulness, the Orca 2 models produced astounding results by largely matching or outperforming models that are five to ten times bigger in size.
The average of all the benchmark results showed that Orca 2 7B and 13B outperformed Llama-2-Chat-13B and 70B and WizardLM-13B and 70B. Only in the GSM8K benchmark, which consists of 8.5K high-quality grade school math problems, WizardLM-70B did convincingly better than the Orca models and Llama models.
While the performance is good news for enterprise teams that may want a small, high-performing model for cost-effective business applications, it is important to note that these models can also inherit limitations common to other language models as well as those of the base model they were fine-tuned upon.
Microsoft added that the technique used to create the Orca models can even be used on other base models out there.
“While it has several limitations…, Orca 2’s potential for future advancements is evident, especially in improved reasoning, specialization, control, and safety of smaller models. The use of carefully filtered synthetic data for post-training emerges as a key strategy in these improvements. As larger models continue to excel, our work with Orca 2 marks a significant step in diversifying the applications and deployment options of language models,” the research team wrote.
More small, high-performing models to crop up
With the release of open-source Orca 2 models and the ongoing research in the space, it is safe to say that more high-performing small language models are likely to crop up in the near future.
Just a few weeks back, China’s recently turned unicorn 01.AI, founded by veteran AI expert Kai-Fu Lee, also took a major step in this area with the release of a 34-billion parameter model that supports Chinese and English and outperforms the 70-billion Llama 2 and 180-billion Falcon counterparts. The startup also offers a smaller option that has been trained with 6 billion parameters and performs respectably on widely used AI/ML model benchmarks.
Mistral AI, the six-month-old Paris-based startup that made headlines with its unique Word Art logo and a record-setting $118 million seed round — also offers a 7 billion parameter model that outperforms bigger offerings, including Meta’s Llama 2 13B (one of the smaller of Meta’s newer models).
TechForgePulse's mission is to be a digital town square for technical decision-makers to gain knowledge about transformative enterprise technology and transact. Discover our Briefings.