
Presented by Zscaler
In 2023, ChatGPT started a technological revolution. Simple interactive AI agents quickly moved into indexing documents, connecting to data sources and even data analysis with a simple sentence. With that success, a lot of people promised last year to deliver large language models (LLMs) soon … and very few of those promises have been fulfilled because:
- We’re building AI agents, not LLMs
- People are treating the problem as one of research, not engineering
- There’s too much bad data
In this article, we’ll examine the role of AI agents in linking LLMs with backend systems. Then, we’ll look at what’s setting up AI agents as the next generation of user interface and user experience (UI/UX). Finally, we’ll talk about why we need to bring back some principles of software engineering that people seem to have forgotten lately.
I want a pizza in 20 minutes
LLMs offer more intuitive, streamlined UI/UX than traditional point-and-click interactions. Let’s suppose you want to order a “gourmet margherita pizza delivered in 20 minutes” through a delivery app.
Using normal UI/UX, this seemingly simple request could require multiple complex interactions and take several minutes. You’ll probably have to:
- Choose the “Pizza” category
- Browse listings and photos
- Check menus for margherita pizza
- See if they can deliver quickly enough
- Backtrack if any criteria aren’t met
We need more than LLMs
LLMs like GPT-3 have demonstrated exceptional abilities in natural language processing (NLP) and generating coherent, relevant responses. Connecting external data sources, algorithms and specialized interfaces to an LLM gives it even more flexibility and analysis capabilities, even opening the door to tasks not yet possible with today’s LLMs.
LLM-based interfaces can be highly complex. Even our “pizza” request needs to connect multiple systems — restaurant databases, inventory management, delivery tracking and more — to complete the order. Yet more connections will be needed to enable greater flexibility, which is crucial to ensure a seamless experience for diverse requests. LLMs can’t do all that by themselves.
AI Agents
LLMs serve as the foundation for AI agents. To respond to a diverse range of queries, an AI agent leverages an LLM in conjunction with several integral auxiliary components:
- The agent core uses the LLM and orchestrates the agent’s overall functionality.
- The memory module enables the agent to make context-aware decisions.
- The planner formulates the agent’s course of action based on the tools at hand.
- Various tools and resources support specific domains, enabling the AI agent to effectively process data, reason and generate appropriate responses. The set of tools include data sources, algorithms and visualizations (or UI interactions).
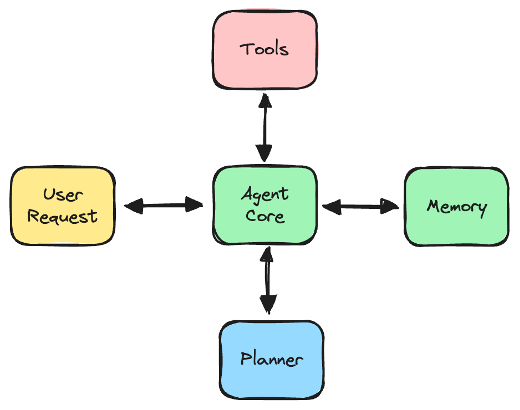
This white paper provides a more complete description of AI agents and components.
Adding LLM-based AI agents to your data is an engineering problem, not a research problem
Natural language can make it much easier to specify use cases for software development. However, the ambiguity of the English language is leading to a new problem in software development, where systems aren’t well specified or understood.
Fred Brooks outlined many central software engineering principles in his 1975 book The Mythical Man-Month, some of which people seem to have forgotten during the LLM rush. For instance:
No silver bullet. No singular development will eliminate the need for proper software engineering practices. Not even LLMs.
The manual and formal documents. Thanks to hype, this is probably the most forgotten principle in the age of LLMs. It’s not enough to say “develop a system that will tell me how to order things like a gourmet margherita pizza in 20 minutes.” This requires documentation of a whole array of other use cases, required backend systems, new types of visualizations to be created, and — crucially — specifications of what the system will not do. “Things like” seems to have become a norm in LLM software development, as if an LLM can magically connect to backend systems and visualize data it has never learned to understand.
(We look at several more of Brooks’ points over on the Zscaler blog.)
In a recent white paper, we’ve addressed the issue of lack of proper specification of software systems, and showed a way we can create formal specifications for LLM-based intelligent systems so they can follow sound software engineering principles.
Bad data
Ensuring LLM-based AI agents work effectively requires more formal data organization and writing methodologies, as discussed on LinkedIn. On top of that, LLM-based systems expect well-written documentation. OpenAI recently stated that it is “impossible” to train AI without using copyrighted works. Essentially, training these models requires not only a tremendous amount of text, but also high-quality text, such as many copyrighted, published works.
Well-written text is even more important if you use RAG-based technologies. In RAG, we index document chunks using embedding technologies in vector databases, and whenever a user asks a question, we return the top-ranking documents to a generator LLM that composes the answer.
Conclusions
There’s an explosion of LLM-based promises in the field, and very few are coming to fruition. In order to realize those promises and build intelligent AI systems, it’s time to recognize we are building complex software engineering systems, not prototypes.
LLM-based intelligent systems bring another level of complexity to system design. We need to consider what it will take to specify and test such systems properly. Finally, we need to treat data as a first-class citizen, as these intelligent systems are much more susceptible to bad data than other systems.
You can read an unabridged version of this article on the Zscaler blog.
Claudionor N. Coelho Jr. is Chief AI Officer at Zscaler.
Sree Koratala is VP, Product Management, Platform Initiatives at Zscaler.
Sponsored articles are content produced by a company that is either paying for the post or has a business relationship with TechForgePulse, and they’re always clearly marked. For more information, contact