
The landscape of generative artificial intelligence is evolving rapidly with the advent of large multimodal models (LMM). These models are transforming the way we interact with AI systems, allowing us to use both images and text as input. OpenAI’s GPT-4 Vision is a leading example of this technology, but its closed-source and commercial nature can limit its use in certain applications.
However, the open-source community is rising to the challenge, with LLaVA 1.5 emerging as a promising blueprint for open source alternatives to GPT-4 Vision.
LLaVA 1.5 combines several generative AI components and has been fine-tuned to create a compute-efficient model that performs various tasks with high accuracy. While it’s not the only open-source LMM, its computational efficiency and high performance can set a new direction for the future of LMM research.
How LMMs work
LMMs typically employ an architecture composed of several pre-existing components: a pre-trained model for encoding visual features, a pre-trained large language model (LLM) for understanding user instructions and generating responses, and a vision-language cross-modal connector for aligning the vision encoder and the language model.
Training an instruction-following LMM usually involves a two-stage process. The first stage, vision-language alignment pretraining, uses image-text pairs to align the visual features with the language model’s word embedding space. The second stage, visual instruction tuning, enables the model to follow and respond to prompts involving visual content. This stage is often challenging due to its compute-intensive nature and the need for a large dataset of carefully curated examples.
What makes LLaVA efficient?
LLaVA 1.5 uses a CLIP (Contrastive Language–Image Pre-training) model as its visual encoder. Developed by OpenAI in 2021, CLIP learns to associate images and text by training on a large dataset of image-description pairs. It is used in advanced text-to-image models like DALL-E 2.
LLaVA’s language model is Vicuna, a version of Meta’s open source LLaMA model fine-tuned for instruction-following. The original LLaVA model used the text-only versions of ChatGPT and GPT-4 to generate training data for visual fine-tuning. Researchers provided the LLM with image descriptions and metadata, prompting it to create conversations, questions, answers, and reasoning problems based on the image content. This method generated 158,000 training examples to train LLaVA for visual instructions, and it proved to be very effective.
LLaVA 1.5 improves upon the original by connecting the language model and vision encoder through a multi-layer perceptron (MLP), a simple deep learning model where all neurons are fully connected. The researchers also added several open-source visual question-answering datasets to the training data, scaled the input image resolution, and gathered data from ShareGPT, an online platform where users can share their conversations with ChatGPT. The entire training data consisted of around 600,000 examples and took about a day on eight A100 GPUs, costing only a few hundred dollars.
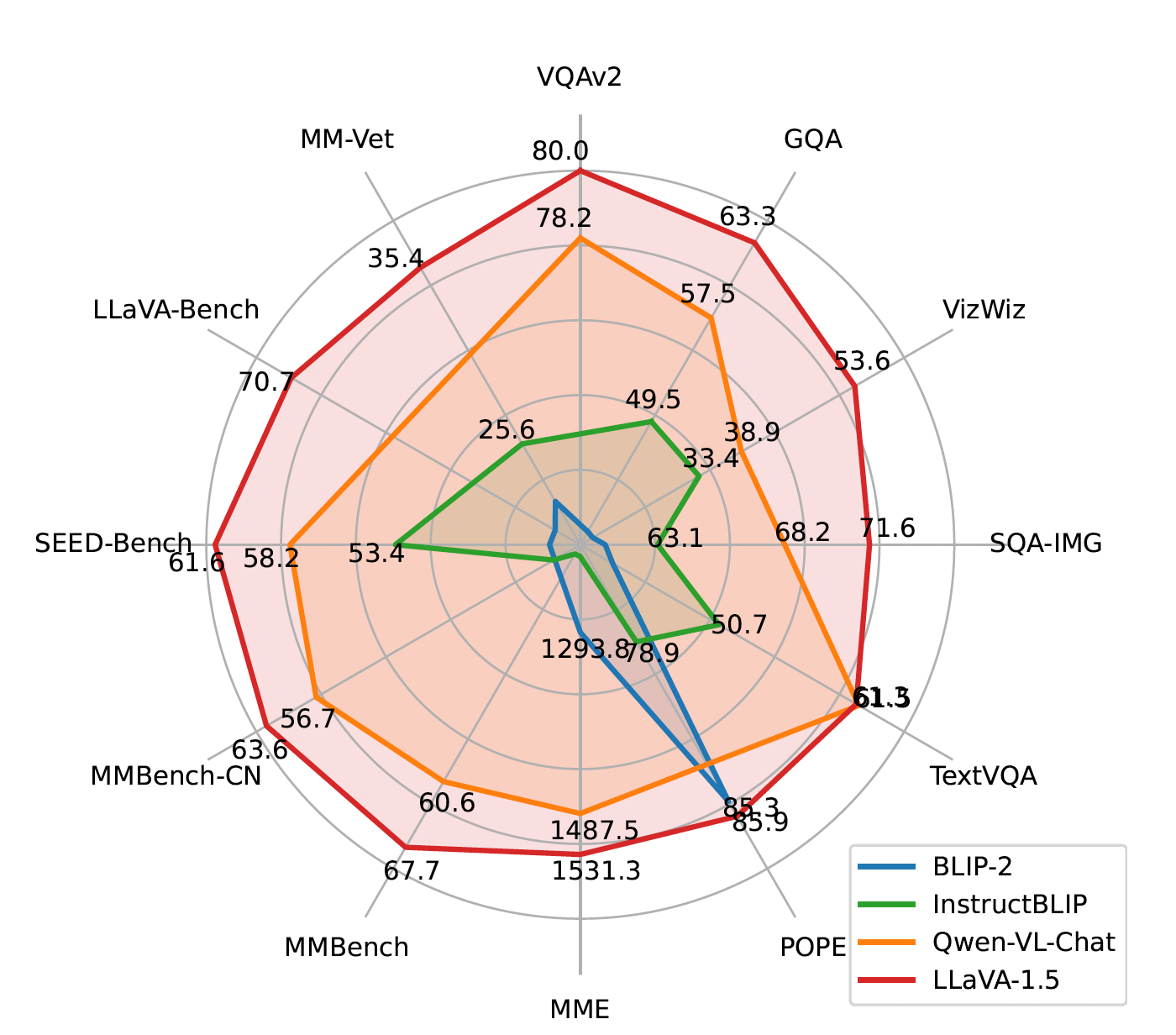
According to the researchers, LLaVA 1.5 outperforms other open-source LMMs on 11 out of 12 multimodal benchmarks. (It is worth noting that measuring the performance of LMMs is complicated and benchmarks might not necessarily reflect performance in real-world applications.)
The future of open source LLMs
An online demo of LLaVA 1.5 is available, showcasing impressive results from a small model that can be trained and run on a tight budget. The code and dataset are also accessible, encouraging further development and customization. Users are sharing interesting examples where LLaVA 1.5 is able to handle complex prompts.
However, LLaVA 1.5 does come with a caveat. As it has been trained on data generated by ChatGPT, it cannot be used for commercial purposes due to ChatGPT’s terms of use, which prevent developers from using it to train competing commercial models.
Creating an AI product also comes with many challenges beyond training a model, and LLaVA is not yet a contender against GPT-4V, which is convenient, easy to use, and integrated with other OpenAI tools, such as DALL-E 3 and external plugins.
However, LLaVA 1.5 has several attractive features, including its cost-effectiveness and the scalability of generating training data for visual instruction tuning with LLMs. Several open-source ChatGPT alternatives can serve this purpose, and it’s only a matter of time before others replicate the success of LLaVA 1.5 and take it in new directions, including permissive licensing and application-specific models.
LLaVA 1.5 is just a glimpse of what we can expect in the coming months in open-source LMMs. As the open-source community continues to innovate, we can anticipate more efficient and accessible models that will further democratize the new wave of generative AI technologies.
TechForgePulse's mission is to be a digital town square for technical decision-makers to gain knowledge about transformative enterprise technology and transact. Discover our Briefings.