
Oh, Google. Will you ever get an AI product release right on the first try?
Less than a month after Google unveiled its long-rumored ChatGPT competitor Gemini to the world in a glossy demo video — only for the company to face criticism for what appeared and was ultimately confirmed to be staged interactions between the presenter and the AI — new research finds that the most powerful version of Gemini available now to consumers, Gemini Pro, falls behind OpenAI’s GPT-3.5 Turbo large language model (LLM) in terms of most tasks.
Yes, you read that correctly: Google’s brand new LLM, the one that has been in development for months at least, performs worse at most tasks than OpenAI’s older, less cutting-edge, free model. After all, ChatGPT Plus and Enterprise paying subscribers can already access and use the underlying GPT-4 and GPT-4V (the multimodal offering) LLMs regularly, and have had access to the former for the better part of this year.
That’s according to the work of a team of researchers from Carnegie Mellon University and one from an enterprise identified as BerriAI.
Their paper, “An In-depth Look at Gemini’s Language Abilities,” was published yesterday on arXiv.org, the pre peer-review and open access science site. As it states plainly near the top: “In sum, we found that across all tasks, as of this writing (December 19, 2023), Gemini’s Pro model achieved comparable but slightly inferior accuracy compared to the current version of OpenAI’s GPT 3.5 Turbo.”
For the Google researchers who have spent hard hours working on Gemini — and their leadership — that conclusion has got to sting. We reached out to Google and a spokesperson responded after this story published, maintaining Google’s own research shows Gemini Pro performs better than GPT-3.5, and that an upcoming, even more powerful version, Gemini Ultra, due out in early 2024, scored higher than GPT-4 on Google’s internal research. Here’s their response in full:
- “In our technical paper [published here], we compare Gemini Pro and Ultra to a suite of external LLMs and our previous best model PaLM 2 across a series of text-based academic benchmarks covering reasoning, reading comprehension, STEM, and coding.
- These results [in Table 2 on Page 7 of the report] show that the performance of Gemini Pro outperforms inference-optimized models such as GPT-3.5, performs comparably with several of the most capable models available, and Gemini Ultra outperforms all current models.
- On Gemini Ultra specifically, on MMLU, it can outperform all existing models, achieving an accuracy of 90.04%. It is also the first model to exceed this threshold, with the prior state-of-the-art result at 86.4%.
“Also, it’s worth reading the Gemini authors discussion on the nuance of these evaluations in the paper (also on the same page), pulling it out for ease:
‘Evaluation on these benchmarks is challenging and may be affected by data contamination. We performed an extensive leaked data analysis after training to ensure the results we report here are as scientifically sound as possible, but still found some minor issues and decided not to report results on e.g. LAMBADA (Paperno et al., 2016).
As part of the evaluation process, on a popular benchmark, HellaSwag (Zellers et al., 2019), we find that an additional hundred finetuning steps on specific website extracts corresponding to the HellaSwag training set (which were not included in Gemini pretraining set) improve the validation accuracy of Gemini Pro to 89.6% and Gemini Ultra to 96.0%, when measured with 1-shot prompting (we measured GPT-4 obtained 92.3% when evaluated 1-shot via the API).
This suggests that the benchmark results are susceptible to the pretraining dataset composition. We choose to report HellaSwag decontaminated results only in a 10-shot evaluation setting. We believe there is a need for more robust and nuanced standardized evaluation benchmarks with no leaked data. So, we evaluate Gemini models on several new held-out evaluation datasets that were recently released, such as WMT23 and Math-AMC 2022-2023 problems, or internally generated from non-web sources, such as Natural2Code.
We refer the reader to the appendix for a comprehensive list of our evaluation benchmarks. Even so, model performance on these benchmarks gives us an indication of the model capabilities and where they may provide impact on real-world tasks.
For example, Gemini Ultra’s impressive reasoning and STEM competencies pave the way for advancements in LLMs within the educational domain. The ability to tackle complex mathematical and scientific concepts opens up exciting possibilities for personalized learning and intelligent tutoring systems.'”
What the researchers tested
The new paper from the CMU and BerriAI researchers goes on to note that they actually tested four different LLMs: Google Gemini Pro, OpenAI GPT-3.5 Turbo, GPT-4 Turbo, and Mixtral 8x7B, the new open-source model from well-funded French startup Mistral that took the AI community by storm last week with its sudden, unceremonious arrival — dropped as a torrent link with no documentation — and its high performance and benchmark scores (standardized evaluations of AI performance).
The researchers used an AI aggregator site, LiteLLM, over a period of 4-days, December 11-15, 2023, and ran all the models through a set of different prompts, including asking them 57 different multiple choice questions “across STEM, the humanities, the social sciences,” as part of a “knowledge-based QA” test.
In that test, “Gemini Pro achieves an accuracy lower than that of GPT 3.5 Turbo, and much lower than that of GPT 4 Turbo,” specifically a score of 64.12/60.63 (out of 100/100) compared to GPT-3.5 Turbo’s 67.75/70.07, and GPT-4 Turbo’s 80.48/78.95. See the top row of the following table included in their paper.
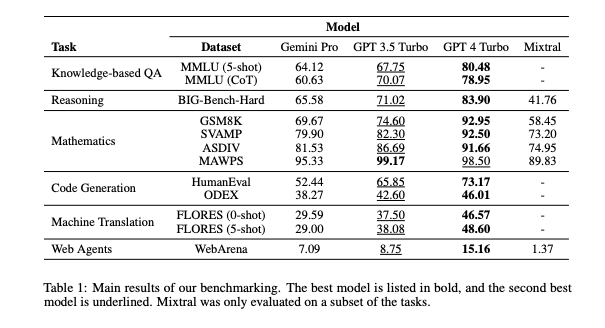
Interestingly, the researchers found that when prompting the different LLMs to choose between answers labeled A, B, C, or D, Gemini disproportionately chose “D” more times than the other models, irrespective of it was the right answer.
“Gemini has a very skewed label distribution, biased towards selecting the final choice of ‘D’ which contrasts to the result of the GPT model, which is more balanced,” the paper states. “This may indicate that Gemini has not been heavily instruction-tuned towards solving multiple-choice questions, which can cause models to be biased with respect to answer ordering.”
In addition, the researchers observed that Gemini was worse than GPT-3.5 Turbo on several specific categories of questions, namely, human sexuality, formal logic, elementary math, and professional medicine. The researchers stated that this was in no small part due to the fact that Gemini refused to answer some questions, stating it could not comply due to its safety and content restrictions, which the researchers counted as an erroneous response in their grading/benchmarking.
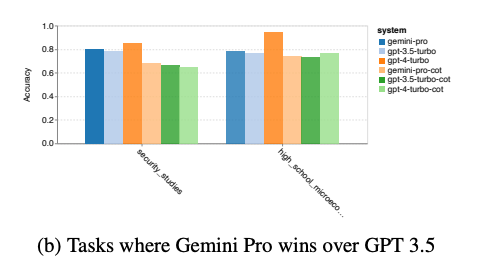
Gemini Pro did outperform GPT-3.5 Turbo in two categories of multiple choice questions — security and high school microeconomics, but “for the two tasks where Gemini Pro outperformed GPT 3.5 Turbo, gains were marginal,” the researchers stated. Also, GPT-4 still reigned king over all the models tested.
To be fair to Gemini, the researchers were careful to note it outperformed GPT-3.5 in one other case: when the output of the LLMs were greater than 900 tokens long (tokens refer to the different numeric values assigned to different words, letter combinations, and symbols, which reflects the model’s internal organization of different concepts).
The researchers tested the models on another category of questions, “general purpose reasoning,” where no answer options were presented. Instead, the LLMs were asked to read a logic problem and respond to it with what they thought was the correct answer.
Once again, the researchers found “Gemini Pro achieves an accuracy slightly lower than that of GPT 3.5 Turbo, and much lower than that of GPT 4 Turbo…Gemini Pro underperformed on longer, more complex questions while the GPT models were more robust to this. This was particularly the case for GPT 4 Turbo, which showed very little degradation even on longer questions, indicating an impressively robust ability to understand longer and more complex queries.”
Yet Gemini did manage to best “all GPT models,” including GPT-4, on two subcategories here: word sorting and symbol manipulation (Dyck language tasks). As the researchers put it: “Gemini is particularly good at word rearrangement and producing symbols in the correct order.”
When it came to math and mathematical reasoning, the researchers identified a similar result as in testing the other subject matter: “Gemini Pro achieves an accuracy slightly lower than that of GPT 3.5 Turbo, and much lower than that of GPT 4 Turbo.”
Think Gemini might redeem itself in programming? Think again. When given two different strings of incomplete Python code to complete, Gemini performed “lower than GPT 3.5 Turbo and much lower than GPT 4 Turbo on both tasks.”
And when asked to act as “web agent,” navigating the public internet and completing tasks on behalf of the user based on prompted instructions, “Gemini-Pro performs comparably but slightly worse than GPT-3.5-Turbo.”
Gemini did outshine all other models in one area that seems uniquely well suited to Google’s prior skill set: translating content between languages. As the researchers note: “Gemini Pro outperforms both GPT 3.5 Turbo and GPT 4 Turbo on 8 out of 20 languages, and achieved the top performances on 4 languages.”
But even this result was sullied by the fact that “Gemini Pro showed a strong tendency to to block responses in approximately 10 language pairs,” suggesting an overzealous content moderation/safety system in place.
What does it mean for Google’s AI ambitions and for users?
The results are clearly a blow to Google’s ambitions to go head-to-head with OpenAI in the generative AI race, and with the more powerful Google Gemini Ultra model not due out until next year, it will likely mean that Google remains behind in AI performance at least until then.
Interestingly, though, the study also showed that Mistral’s hit new LLM Mixtral 8x7B — which utilizes a “mixture of experts” approach, wherein several different smaller AI models are chained together, each handling different sets of tasks for which they are ideally specialized — also performed much worse than OpenAI’s GPT-3.5 Turbo across the board, for the most part. And Gemini Pro “outperforms Mixtral on every task that we examined,” according to the researchers.
That suggests a bright spot for Google’s AI work: it is still better than the cutting-edge open source.
Yet, overall, it is hard not to walk away from this study with the impression that OpenAI is, for now, still the king of consumer and enterprise-facing generative AI.
AI influencers such as University of Pennsylvania Wharton School of Business professor Ethan Mollick largely seem to agree. As Mollick posted on X today: “For most individual cases, you want to use the best AI & that is clearly still GPT-4…at least until Gemini Ultra is released in the new year.”
TechForgePulse's mission is to be a digital town square for technical decision-makers to gain knowledge about transformative enterprise technology and transact. Discover our Briefings.